
Pankaj Parashar
Designer. Developer. Writer.
London, UK

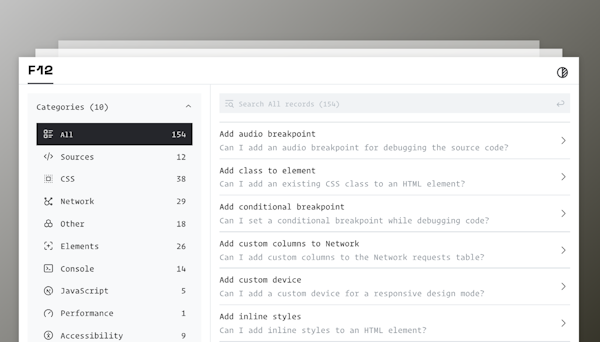

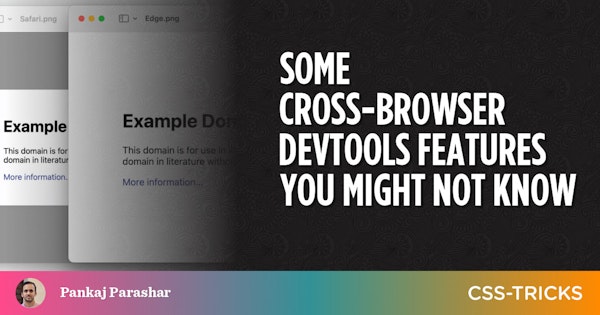
2023
Projects






2022
2020
2015
2013
2014
2012







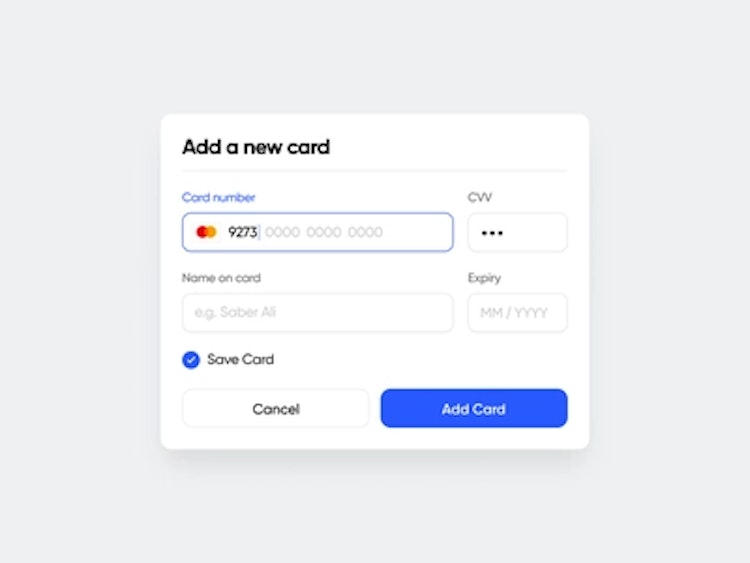

2016



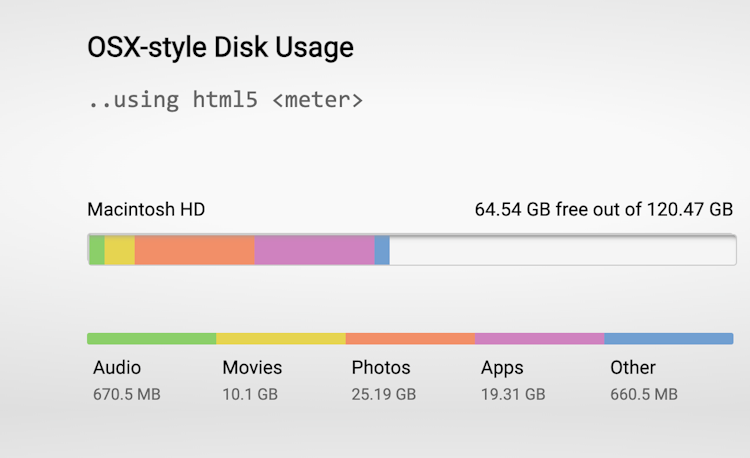
2021


Moved to London

Registered pankajparashar.com!
Countries visited

USA

Australia

United Kingdom
2024
Designer. Developer. Writer.
London, UK
2023
Projects
2022
2020
2015
2013
2014
2012
2016
2021
Moved to London
Registered pankajparashar.com!
Countries visited
USA
Australia
United Kingdom
2024

